Cloud-agnostic Kubernetes Clusters
Managed Kubernetes usually ties you to a single cloud vendor. Here's the architecture we use at Berops to run truly cloud-agnostic, multi-cloud clusters — without long-term lock-in.
Managed Kubernetes usually ties you to a single cloud vendor. Here's the architecture we use at Berops to run truly cloud-agnostic, multi-cloud clusters — without long-term lock-in.
Kubernetes is often referred to as “the operating system of the cloud”. It gives freedom to build feature-rich platforms for operating your application stacks. Kubernetes itself is cloud-agnostic and the fact that it’s open-source may imply no vendor lock-in. However, all real-world installations come with quite an opposite experience.
With managed Kubernetes, the vendor of the compute layer is the vendor of the Kubernetes distribution as well. This is a binding that may not be desired in all cases. There are Kubernetes distributions, such as Openshift or Rancher, that focus exclusively on Kubernetes life-cycle management, but they come opinionated with specific customizations, performed by their vendors. No matter whether you choose a K8s cluster lifecycle manager that’s bound to the compute layer automation or not, any decision you make will tie you in this setup for rather a long time. Moreover, migrating production workloads between clusters is not a straightforward activity. Effectively, this leaves you with no room for a low-barrier pivot action in the orchestration of your Kuberenetes cluster fleet.
At Berops, this has led us to figure out if we can open the door to a higher degree of freedom and flexibility for consumers of Kubernetes stacks. Can we design an architecture that would allow our customers to benefit from the strong features of individual public cloud providers without a long-term vendor lock-in? Can we build a managed multi-cloud Kubernetes cluster manager that provides enough flexibility for pivots, depending on the evolution of client demands, ideally with the aim to lower the risks and in turn, the cost of these changes?
The biggest hurdle in building a cloud-agnostic managed Kubernetes lies in the connectivity layer. Deploying Kubernetes across multiple cloud providers means entering the world of heterogeneous networking stacks. A simple example would be the termination of a public IPv4 address; some providers assign it to the node interface directly, some assign public IPs to the router interfaces with a 1:1 NAT configuration to the node itself.
The specifics of a cloud provider networking stack can be abstracted by deploying a VPN across the compute layer. A subnet is created where each node has an interface available and the cloud-provider specifics are abstracted. This setup provides:
Placing a VPN underneath Kubernetes comes with its costs. As the traffic leaving the cloud-provider goes out into the open, the traffic encryption is mandatory. This implies performance impacts on the communication layer (latency and throughput bottlenecks) and eventually, depending on the infrastructure providers involved, a higher bill for the infrastructure. In most cases though, these factors are negligible. Of course, unless the applications operate in a very latency-sensitive or high-throughput scenarios. We have benchmarked these setups. The data can be found in our earlier blog post.
A practical baseline topology is to distribute control-plane and compute-plane node pools across multiple providers while exposing ingress through provider-local load balancers. This keeps workloads resilient to provider or region-level failures and makes capacity pivots between providers easier over time.
Ensuring the availability of cluster-hosted services to the outside world requires a dive beneath the surface. For the sake of simplicity, let’s consider only two categories of load-balancers. The control-plane load-balancer (i.e. the Kubernetes API loadbalancer) and the ingress loadbalancers (assuming the HTTP(S) loadbalancers and any NodePort loadbalancers in general in this context).
The stack that is being described in this article has strong disaster recovery and high-availability aspirations. With the VPN overlay, each nodepool can be hosted at a different cloud-provider. Therefore, the architecture of the loadbalancers needs to supports these scenarios. This is achieved through DNS Round Robin mechanism. DNS Round Robin is a setup where multiple IP addresses are linked to a single hostname. For each DNS query, the DNS resolver sends a permutated list of IPs. The client has a failover option in case the first attempted connection fails, simply by trying to make a connection to the next IP address from the list.
This way several load-balancers (across multiple providers, if so desired) serve as entrypoints into the multi-cloud Kubernetes cluster. This concept holds well through the disaster-recovery scenarios. If a load-balancer from region or cloud provider suffering an outage becomes unreachable, the clients automatically fail over to another load-balancer instance running in a different cloud-provider. Analogically, this approach works well for traffic originating internally from the cluster itself (the calls towards the Kubernetes API), from within the inner boundaries of the VPN network. Let’s consider a deployment meant to be resilient against a provider-wide outage. In order to ensure the availability of the control-plane, the cluster’s etcd nodes need to have presence across three different cloud providers (implied by the requirements of the Raft algorithm behind etcd). The load-balancers would need to be deployed across two or more cloud-providers.
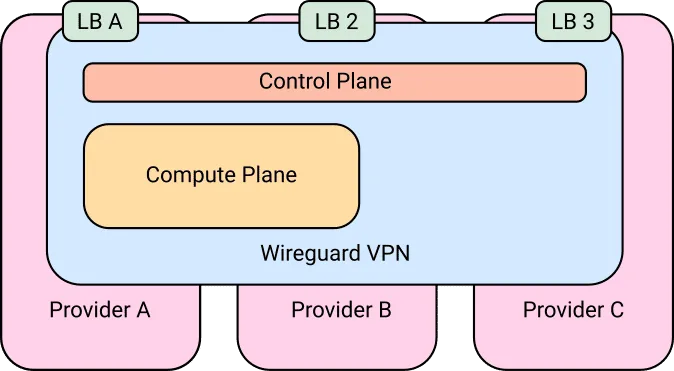
Above is a high-level design example of a Kubernetes cluster spread across three cloud providers. Master nodes take full advantage of this potential and with the outlined configuration make the control plane resilient to a provider-wide outage. The compute plane is hosted across two cloud providers. This is a basic, but already useful setup. Load balancers are present in all three cloud providers.
Once the above described is clear, figuring out a storage layer isn’t too difficult. Simply a Longhorn or a Ceph-Rook combo running across the block devices of the cluster nodes themselves would work just fine in most cases. Are there things to watch out for? Yes, indeed, at least some. I/O latency and cloud provider egress traffic costs are the most sensitive ones. The proposed mitigation is straightforward – the workload should be placed close to the data. Ideally, within the boundaries of a single cloud provider, region or zone. Good news is that this approach doesn’t compromise on the high-availability aspect of this setup.
Useful configuration can be achieved by using cross-provider dataset replication combined with cloud provider preferences for scheduling (spec.affinity.nodeAffinity.preferredDuringSchedulingIgnoredDuringExecution). This approach assures that the workload is responsive since it is close to the data. If a disruption occurs, there’s a data replica located in another cloud provider and the workload can be relocated there in order to achieve a quick recovery. Of course, there are situations when these tangible benefits justify the extra cost of the implied overhead of multi-cloud setups (extra costs of storage, compute and cross-provider egress bills).
The stack outlined in this article has been built, tested, benchmarked and its provisioning has been automated here. Our architecture has the ability to bring you closer to your high-availability and disaster-recovery goals without the inherent complexity of service meshes (typically used in these scenarios). This is the true beauty of the newly outlined setup. The proposed design liberates you from the IaaS vendor-lock in. Moreover, there’s no reason to be afraid of doing cross-cluster migration under full production load. On top of that, in combination with an on-premise nodepool that you already own or rent, you can benefit from cloud-bursting (for your ML workloads, planned marketing or promo events) while keeping the infrastructure costs sane.
